By B. Staffan Lindgren, Professor Emeritus
A while back, a paper accepted by The American Statistician entitled “The ASA’s statement on p-values: context, process, and purpose” was posted to the American Statistical Association website. The gist of the paper was that many disciplines rely too much on the p-value as the sole indicator of research importance. Not surprisingly, the paper received considerable attention.
Over my career, I had a love-hate relationship with statistics, knowing just enough to be dangerous, but not enough to really understand what I was doing. Consequently I relied on packaged software and/or colleagues or students who were more quantitatively minded than myself. For example, I generally made sure that a graduate student committee had at least one member with some strength in statistics to make sure I would not leave the candidate stranded or led astray. So if you read my thoughts below, keep in mind that I tread on very thin ice here. I fully expect some disagreement on this, but that is the way it is supposed to be. Ultimately it is your responsibility to understand what you are doing.
The approaches and tools for statistical analysis have changed a lot since my student days, which was at the dawn of mainframe computers for general use, on which we could use a software package called Textform rather than typing the thesis on a type writer as I (read “a secretary I hired and almost drove to depression”) did for my masters. My first visit to a statistical consultant at Simon Fraser University ended with the advice that “This data set can’t be analyzed, it contains zero values.” The software of choice was SPSS, which did not allow for any complexity, so I did a fair bit by hand (which might have been a good thing since it forced me to think about what I was doing, but certainly did not prevent errors). Later in my career it was sometimes a struggle to decide among differing opinions of statisticians what was and was not appropriate to use, but with a little help from my friends I think I managed to negotiate most of the pitfalls (no pun intended) fairly well.

The statistic-phobic author with his eponymous insect trap, preparing to gather data and test hypotheses. Photo: Ron Long.
One of the issues with our reliance on p-values is that it is tempting to do post-hoc “significance-hunting” by using a variety of approaches, rather than deciding a priori how to analyze the data. Data that show no significance often remains unpublished, leading to potential “publication bias”. In part this may be the result of journal policies (or reviewer bias), which tends to lead to rejection of papers reporting ‘negative’ results. We have also been trained to use an experiment-wise alpha of 0.05 or less, i.e., a significant result would be declared if the p-value is lower than 0.05. There are two problems with this. First, it is an arbitrary value in a sense, e.g., there really is no meaningful difference between p=0.049 and 0.051. Furthermore, the p-value does not really tell you anything about the importance of the result. All it can do is give some guidance regarding the interpretation of the results relative to the hypothesis. I have tried to make students put their research in context, because I believe the objective of the research may dictate whether or not a significant p-value is important or not. I used to work in industry, and one of the reasons I left was that recommendations I made based on research were not always acted upon. For example, pheromones of bark beetles are often synergized by various host volatiles. But whether or not they are may depend on environmental factors. For example, just after clear cutting the air is likely to have high levels of host volatiles, thus making any host volatile added to a trap ineffective. However, a company may make money by selling such volatiles, and hence they would tend to ignore any results that would lead to a loss of revenue. On the other hand, one could argue that they have the customers’ best interest in mind, because if host volatiles are important under some circumstances, it would be detrimental to remove them from the product.
This leads to my thoughts about the power of an analysis. The way I think of power is that it is a measure of the likelihood of finding a difference if it is there. There are two ways of increasing power that I can think of. One is to increase the number of replications, and the other is to use a higher alpha value. It is important to think about the consequence of an error. A Type I error is when significance is declared when there is none, while a Type II error is when no significance is found when in fact there is one. Which of these is most important is something we need to think about. For example, if you worked in conservation of a threatened species, and you found that a particular action to enhance survival resulted in a p-value of 0.07, would you be prepared to declare that action ineffective assuming that it wasn’t prohibitively expensive? If you have committed a Type II error, and discontinue the action, it could result in extinction of the threatened species. On the other hand, if you test a pesticide, would a significant value of 0.049 be enough to decide to pursue the expensive testing required for registration? If you have committed a Type I error, the product is not likely to succeed in the market place. If the potential market is small, which tends to be the case for behavioural chemicals, it may not be feasible to use this product because of the high cost, which has nothing to do with statistical analysis, but could be the overriding concern in determining the importance of the finding.
One area where the sole use of p-values can become very problematic is for regressions. The p-value only tells us whether or not the slope of the line is significantly different from zero, and therefore it becomes really important to look at how the data are distributed. An outlier can have a huge impact, for example (see figure). As an editor I saw many questionable regressions, e.g., with single points driving much of the effect, but which in the text were described as highly significant.
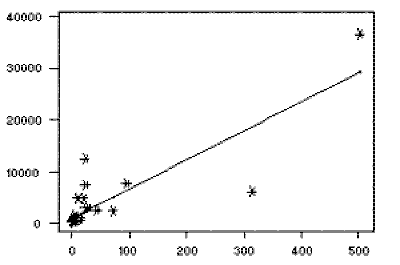
Fig. 1. An example of where a single point is driving a linear regression. Take it away and there is no apparent relationship at all. Figure from http://www.stat.yale.edu/Courses/1997-98/101/linreg.htm
Finally, we need to keep in mind that a significant p-value does not indicate certainty, but probability, i.e., at p=0.05, you would expect to get the same result 19 of 20 times, but that still means that the result could be the result of chance if you only ran the experiment once. (If you run a biological experiment that yields a p-value close to 0.05 a number of times, you would soon discover that it can be difficult to get the same outcome every time). Depending on the context, that may not be all that confidence inspiring. For example, if someone told you that there was only a 5% probability that you would be get seriously sick by eating a particular mushroom, wouldn’t that make you think twice about eating it?? On the other hand many of us will gladly shell out money to buy a 6/49 ticket even though the probability of winning anything at all is very low, let alone winning the jackpot, because in the end we are buying the dream of winning, and a loss is not that taxing (unless you gamble excessively of course). I consider odds of 1:8000 in a lottery really good, which they aren’t of course, evidenced by the fact that I have never won anything of substance! So relatively speaking, 1:20 is astronomically high if you think about it!
Why am I bothering to write this as a self-confessed statistics phobe? I have mainly to emphasize that you (and by “you” I primarily mean students engaged in independent research) need to think of statistics as a valuable tool, but not as the only, or even primary tool for interpreting results. Ultimately, it is the biological information that is important.






